
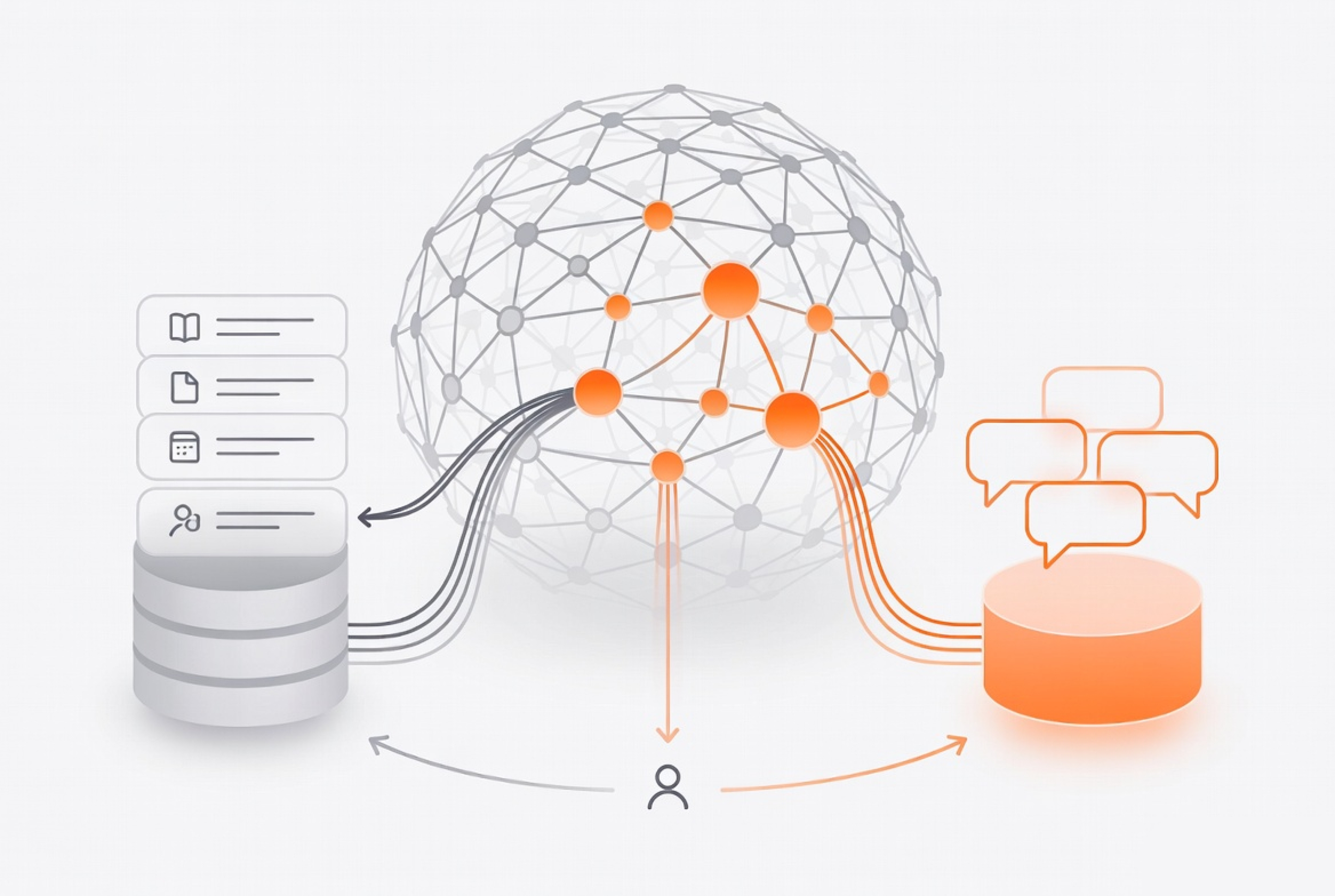
The issue that enterprises today have is a huge problem because they generate more data than they can handle. The majority of this information is not structured in any form, it is papers, reports, emails, logs, spreadsheets, and infinite internal files. The connections within this data are hard to follow and this complicates overall answering of simple questions to get the full picture.
The teams do not work because:
- Information exists in numerous stand-alone systems.
- There is a lack of structure in information.
- There is no clarity in relationships between concepts.
Graph RAG comes in at this point. In contrast to AI-based systems, Graph RAG provides a predictable, deterministic and fully explainable method of knowledge retrieval. It is not based on machine learning. Instead it lists information in a clean and linked structure which makes complex answers easy to locate.
1. What Is Graph RAG?
Graph RAG is a recall technique based on knowledge graphs, and not artificial intelligence models. It is not based on LLMs, embeddings, or generative methods. Rather, it solves problems by traversing an organized relationship within a graph database.
In simple terms:
A knowledge graph is a form of real world information in the form of connected nodes.
Graph RAG provides these links to provide correct answers.
Since it is deterministic, it only provides facts that exist in the graph.
This method prevents hallucinations. The system is unable to create information since it simply recalls what is specifically stored and coded. In industries that are concerned with accuracy, this is a significant benefit.
2. The Building Blocks of Graph RAG
A Graph RAG system is constructed based on clarity, organised elements:
Nodes (Entities)
These are items or concepts, products, people, suppliers, regulations, documents or processes.
Edges (Relationships)
The way nodes are connected is indicated by edges:
- “belongs to”
- “depends on”
- “is part of”
- “causes”
- “complies with”
Such relations reflect reality.
Properties
Nodes and derivatives are both carrying some details. For example:
Name, location, and risk score can be a part of a supplier node.
A dependency strength or timelines may be present in a relationship.
Graph Query Engines
Such engines (such as Cypher, Gremlin, or GraphQL-based queries) can access a particular piece of information by traversing connected edges of the graph.
3. How Graph RAG Differs From AI-Based RAG
Classical RAG systems that incorporate AI are both search and generative. They reconsider text fragments and leave an LLCM to generate a response. Such an approach has its limitation:
AI RAG
- Probabilistic – outcomes are based on model training.
- Ability to hallucinate; can give false answers, but is sure of them.
- Difficult to audit – course of action is ambiguous.
- Creative but inconsistent
Graph RAG
- Deterministic – responses are based on graph data.
- No delusions – something can be tracked down.
- Completely auditable – each answer indicates its origin.
- Addresses controlled settings very well.
- To them predictability and clarity are more important than flexible natural language responses.
- Graph RAG will provide them precisely with that.
4. Benefits of Graph RAG for Enterprises
- 100% Reliable Answers
It does not give any guesswork, the information that appears in the graph only. - Complex Query Navigation
It is able to pursue multi-step relationships, which include:
Who are the suppliers in Region A, which are dependent on Component B? - Scales to Millions of Nodes
The networks with many nodes are dealt with by graph databases. - Ideal for Analytics and Compliance
The relationship is structured ensuring that lineage, dependencies and risks are easily tracked. - Reduces Business Risk
Business enterprises obtain evidence-based answers that are clean to aid decision-making.
5. Use Cases
- Supply Chain Dependency Mapping
Companies will be able to overlay what is dependent and not dependent on a supplier, providing an understanding of risk and performance choke points. - Regulatory Compliance Checks
Clear audit trails allow trace of rules, policies and required actions by finance and insurance teams. - Healthcare Treatment Graphs
The medical teams can associate symptoms, treatments, and guidelines to make exact references without being exposed to hallucinations. - Enterprise Documentation Retrieval
Documents, authors, topics, and dependencies can be related to enable faster and more accurate internal search by organizations.
6. Implementation Challenges (+ Solutions)
Construction of Graph RAG system is potent, in addition there are pitfalls:
- Data Modelling Complexity
The ability to create the appropriate schema is a skill.
Solution: Professional architects create graphs which capture actual business logic. - Normalization and Cleaning
Unstructured data requires uniformity prior to the ability to chart it.
Solution: Clean and categorize data using solution ETL pipelines and domain experts. - Integration With Legacy Systems
Old systems possibly do not work with modern graph structures.
Solution: construct middleware and connectors to integrate information in a secure way.
7. How Chimera Helps Build Graph RAG Systems
Chimera is an enterprise gradeGraph RAG builder. Their strengths include:
- Intensive knowledge of Neo4j, TigerGraph, and DGraph.
- Writing scalable and variably-capable graph designs.
- Creation of ingestion pipelines of normalized data that is clean.
- Stability in the process of governance, versioning and maintainability.
Conclusion
The future of enterprise knowledge retrieval is graph RAG. It provides an alternative to AI-based systems that is as clean, reliable, and predictable as organizations require it to be. Graph RAG allows enterprises to realize the real power of their data without risking hallucinations because of its clear relationships and deterministic outcomes and full auditability.











